

For years, validation in regulated labs has been shaped by a simple instinct: test everything, document everything, leave nothing uncovered.
That mindset made sense in the early days of digital adoption. As labs moved from paper records and spreadsheets into software-driven workflows, regulators needed assurance that computer systems would not compromise product quality, patient safety, or data integrity. That gave rise to Computer System Validation, or CSV.
But today, many labs are asking a fair question: if software vendors are already validating their platforms, and if not every feature carries the same level of risk, why are teams still spending months retesting everything? Conversations with industry leaders, including Scott Krieger, Quality Director at Labbit, highlight how common this tension has become–and how urgently labs are looking for more practical, risk-based approaches.
That question is what sits behind the industry’s shift toward Computer Software Assurance, or CSA. CSA does not lower the bar for compliance. It changes where validation effort is focused: away from exhaustive documentation and toward risk-based assurance of the functions that matter most. As the FDA’s 2022 draft guidance and related industry frameworks emphasize, the goal is not to test less. It is to test smarter.
And that brings us to the real challenge.
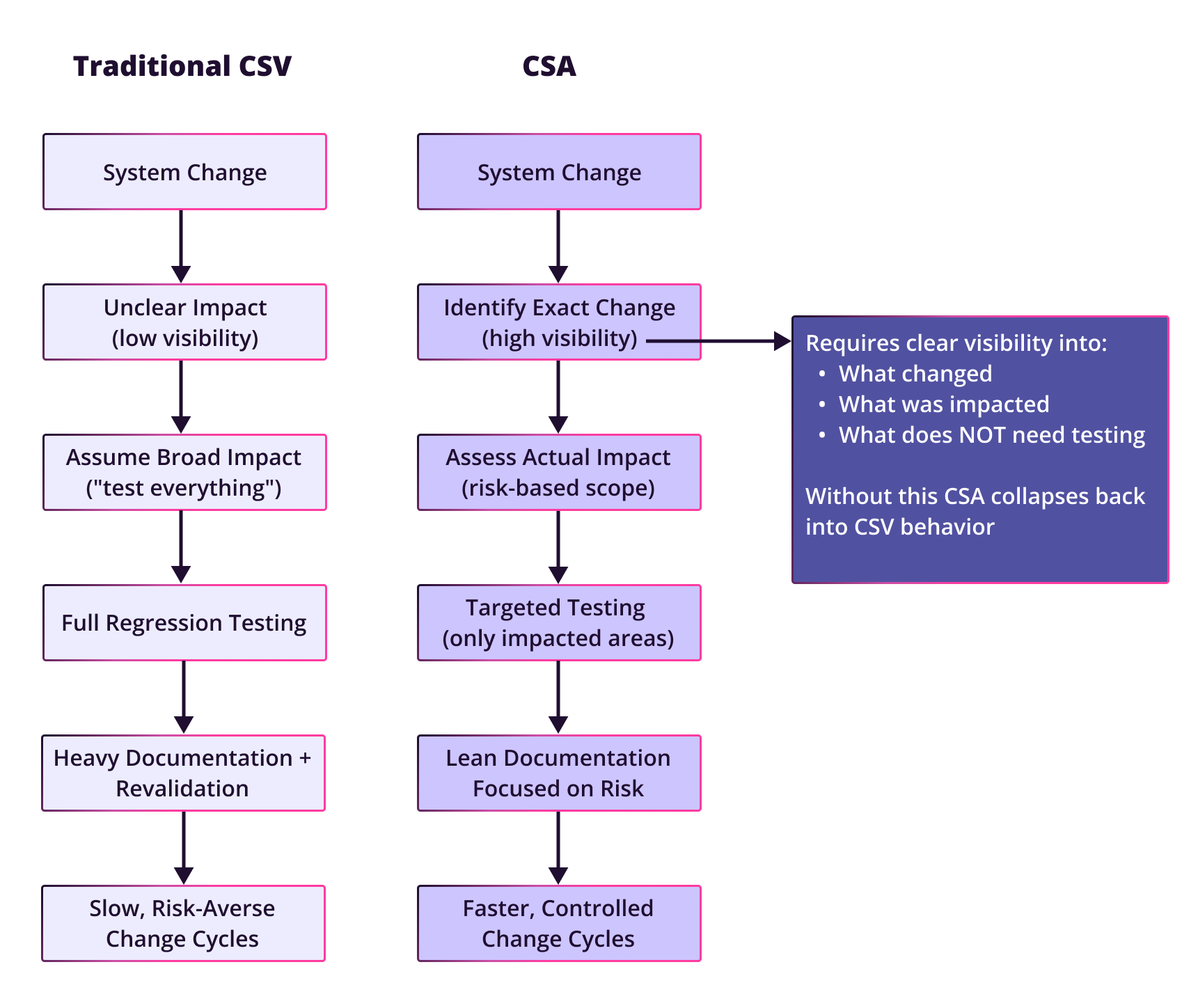
For many labs, the barrier to adopting CSA is not philosophical. It is practical. You cannot take a truly risk-based approach if you cannot clearly see what changed, what was affected, and what actually needs to be revalidated. That is where change visibility becomes critical.
Why traditional CSV creates so much friction
Traditional CSV often becomes over-scoped because teams are operating with incomplete information. When a configuration changes, the safest response is often to assume the blast radius is large and test broadly.
As Scott put it, “validation is often over-scoped because of uncertainty.” In practice, that uncertainty creates a familiar pattern: a change is made, the exact impact is hard to isolate, and the team falls back on system-wide revalidation or broad regression testing just to be safe.
That creates several problems.
First, the documentation burden becomes enormous. The supporting CSA guidance describes CSV as a model built around large validation packages, extensive retesting, and heavy administrative overhead. It also notes that organizations commonly associate CSV with long implementation timelines and frequent revalidation cycles.
Second, teams end up testing low-risk features with the same intensity as high-risk ones. For instance, if a print button fails, it may be inconvenient, but it is not equivalent to a rounding error in a clinical result. One may be annoying. The other could create a patient safety issue.
Third, this slows innovation. Every change becomes expensive. Every update feels risky. And every improvement to the system carries a validation tax that makes teams hesitate before moving forward.
What CSA changes
CSA was designed to address exactly that problem.
Rather than asking, “Did we test everything?”, CSA asks, “Do we have assurance that critical functions work and that risk is controlled?” That shift allows organizations to focus validation effort on functions that directly affect patient safety, product quality, data integrity, and regulatory compliance. It also explicitly encourages teams to leverage vendor testing where appropriate instead of retesting standard functionality from scratch.
Scott described the shift this way: “With CSA, it’s really work smarter, not harder.” That means evaluating requirements against vendor testing, applying a risk-based lens, and then targeting internal validation effort where it adds real value.
The supporting CSA document makes the same case. It frames CSA as a model built around risk-based testing, vendor leverage, continuous assurance, and streamlined documentation. It also notes that organizations adopting CSA commonly see substantial reductions in validation time and documentation burden, while improving focus on the areas that matter most.
But there is still a catch.
CSA depends on being able to define impact with confidence. If you cannot clearly see what changed, you will still tend to over-test.
The missing piece: change visibility
This is where many labs get stuck.
In theory, CSA sounds straightforward. In practice, traditional systems often make it hard to answer basic questions:
- What changed between one version and the next?
- Was this an added task, an edited field, or a removed workflow step?
- What parts of the process were actually affected?
- What can we safely leave alone?
In many legacy environments, especially heavily customized or poorly transparent ones, teams do not have an easy way to detect configuration changes. Instead, someone may have to inspect code repositories, interpret change notes manually, or simply guess at the scope of the change. When that happens, broad retesting becomes the default.
As Scott put it, “When configurations are made, they’re not highly detectable,” and that lack of visibility “typically leads to over-testing.”
That is the real obstacle to CSA adoption. Not a lack of willingness to be risk-based, but a lack of confidence in what the risk actually is.
What good change visibility looks like
Good change visibility makes the delta obvious.
Scott’s definition was practical: the system should make it easy to compare the historic state and the new state, and clearly show what was added, edited, removed, or archived. Better still, those differences should be visible through the user interface, not buried in code or change logs.
That level of clarity is increasingly enabled by platforms like Labbit, where built-in configuration versioning allows teams to view configuration histories in context and compare versions side by side, with differences automatically highlighted.
That matters because a visual diff shortens the distance between change and validation decision.
If a team can see that one task was edited, one field was added, and no other workflow components changed, they can validate that exact scope. They do not need to retest the entire process out of fear that something invisible may have shifted elsewhere.
Scott summarized it well: “Having those changes explicitly delineated reduces the amount of overall testing needed because you could very explicitly risk what is the change and what is not impacted.”
That is the bridge between change visibility and CSA. Visibility gives teams confidence. Confidence enables targeted validation, and targeted validation is what makes CSA practical.
A simple example: one change, two very different validation responses
Imagine a workflow with 120 tasks. A single field is edited in one task.
In a low-visibility system, the validation response often looks like this:
- - someone inspects the code or configuration manually,
- - tries to interpret what changed,
- - worries that the change may have affected other behavior,
- - and broadens testing to compensate for uncertainty.
That is how small changes become large validation events.
Now imagine the same change in a system with strong visibility:
- - the edited task is clearly flagged,
- - the previous and current versions are shown side by side,
- - the team can see exactly what changed,
- - and testing can be targeted to that field, that task, and any directly affected downstream behavior.
That is a very different validation exercise.
Scott framed the contrast in simple terms: in the old model, “they’re likely gonna over-test because they may not be very clear on what that change impacts.” With proper visibility, “your testing gets very targeted to the change impacted and not necessarily testing out of fear.”
That difference is not just about efficiency. It is about confidence. QA, IT, and lab operations can all work from the same understanding of scope instead of relying on assumptions.
The operational impact on labs
When labs improve change visibility, the benefits extend beyond validation. And increasingly, that visibility is being driven by systems with built-in configuration versioning, like Labbit’s, which provide a clear, traceable view of how configurations evolve over time.
Scott called out several practical gains:
- - reduced time evaluating change,
- - reduced testing driven by uncertainty,
- - improved confidence in test coverage,
- - reduced paperwork,
- - and faster turnaround times.
Those outcomes map directly to the goals of CSA. The CSA guidance also reinforces this point, noting that organizations using CSA can implement changes faster, reduce validation overhead, and spend more effort on quality and process improvement rather than documentation for documentation’s sake.
With built-in configuration versioning, teams are no longer piecing together what changed from scattered records. They can see configuration histories in context, compare versions directly, and understand differences with far greater clarity. That level of visibility removes much of the ambiguity that traditionally drives over-testing and excessive documentation.
In other words, change visibility does not just simplify validation. It also changes how teams think about updating systems in the first place.
Instead of seeing every update as a potential validation nightmare, teams can begin to see changes as manageable, reviewable, and testable in proportion to their actual risk.
That is a healthier operating model for modern labs, especially those trying to evolve quickly.
What comes next: AI, automation, and proactive assurance
If change visibility is the foundation, AI is likely the next layer.
Scott expects validation to keep moving in this direction. He is already seeing CSA gain traction in organizations that historically would have defaulted to more rigid validation models. He sees AI as the natural extension of that trend, not because it supports human judgment, but because it can significantly reduce the manual burden around change analysis and test generation.
His view was clear: AI will increasingly help “determine the impact of that change” and “automate the test scripts” around what was modified.
That future is especially compelling in systems that already understand their own configuration state and relationships. Once a system can identify exactly what changed, AI can begin to assist with the next question: What should be tested now? Labbit is already exploring this direction with an upcoming validation assistant that leverages its graph-based understanding of system configuration to intelligently generate and execute test scripts based on real change impact.
That moves validation from reactive effort toward proactive assurance.
The takeaway
CSA is often described as a smarter, more modern, approach to validation. That is true, but only if labs have the visibility needed to apply it with confidence.
Without change visibility, CSA remains an aspiration. Teams still over-test because they cannot clearly see the impact of change.
With change visibility, the model starts to work the way it was intended to:
- - risks become easier to define,
- - validation scope becomes easier to target,
- - and changes become easier to release without unnecessary overhead.
As Scott put it, the old problem was that teams were “testing out of fear.” The opportunity now is to validate with clarity instead.
Not less rigor. Better focus.
If change visibility is what makes CSA practical, the next step is understanding how to operationalize it. That's exactly what we explored in our webinar, Configuration Versioning for LIMS: Bringing Software-Style Releases to Laboratory Systems, where we went beyond basic change tracking to show how versioned configuration — deployed as structured changesets — gives teams a clear, auditable view of what changed, what was impacted, and what actually needs to be validated.

Now, in Part 2, Configuration Versioning and Validation: Managing Compliant LIMS Change, live on July 29, 2026 from 10:00–10:45 AM, Scott Krieger picks the conversation back up — moving from the mechanics of change management into validation governance itself. He'll dig into how structured, versioned changesets let teams define validated system state, scope impact assessments with precision, and build audit-defensible narratives grounded in configuration versions rather than ad hoc change. It's the natural extension of everything he described here: not testing less, but validating with clarity instead of fear.





