

Biomedical data spans many forms and applications, from drug discovery to healthcare and clinical research.
But when data is unclear or questionable, it undermines data management, compromising both accuracy and integrity and, ultimately, good scientific practice.
Following the FAIR data principles, metadata on a dataset’s origin, lifecycle, transformation, and downstream processing provide scientists and organizations with reliable and precise knowledge for accurate interpretation and reproduction.
Plus, it helps informaticians pinpoint inconsistencies and root causes if problems arise.
This is where data provenance and data lineage come into play.
The two terms are often used interchangeably, but, in reality, they offer distinct perspectives on understanding the history and flow of every data set.
What Is Data Provenance?
Data provenance is the detailed record of its origins, including the processes and the methods that produced it. Data provenance records the original source and context of a data point, where a dataset came from, and under what conditions it was created.
In pharmaceutical and clinical diagnostics labs, this information is crucial for assessing data quality, reliability, and trustworthiness, which directly affect drug quality and patient health.
Data provenance traces the origin and changes of data over time, as datasets are altered, resulting in a changed state. And, any data set with a changed state is considered to be a new data set.
So, as data evolves, data provenance answers questions about the source, authenticity, and validity of a piece of data, documenting the entities, activities, and people involved in its production.
Why Is Data Provenance Important?
Data provenance emphasizes the authenticity and integrity of data so that its source and history are verifiable. It's about establishing trustworthiness by providing a clear audit trail of the data's past and, at the same time, making it possible to track the reasons behind any problem with a particular piece of data.
How Is Data Provenance Used In The Lab?
In a pharma laboratory setting, for example, generating a full provenance record on a measured volume means that the lab staff can fully demonstrate how they know that a certain volume was measured.
They will need to be able to respond to questions like:
- Who measured the volume?
- When was it measured?
- At which facility was it measured?
- What system or instrument was used?
- Why was it measured? Is it part of an SOP? And if yes, which SOP step?
To be able to quickly and reliably answer questions like these, you’ll need a systematic capture of consistent metadata for every specimen in a standardized and reviewable format.
What Is Data Lineage?
Data lineage is tracking and documenting the movement, aggregations, and changes made to data throughout its lifecycle, as well as its origin source. It visualizes the chronology of a data set as it moves through various systems and processes all the way to consumption in reports, analytics, and decisions.
Data lineage ensures that all data – such as lab results, patient data, clinical trial data, and preclinical test information – can be traced from its origin to its current state.
Why Is Data Lineage Important?
Data lineage offers transparency over data flow, providing insights into how data is derived, altered, and used. It strengthens data accuracy, helps trace anomalies to their source, and enhances auditability and regulatory compliance.
How Is Data Lineage Used In The Lab?
In the context of clinical research, for instance, data lineage and provenance mitigate problems related to the reproducibility of research projects and their results.
Indeed, today, despite the abundance of published research, just a small part of it can be replicated reliably and in full. This is mainly because much of the research findings out there either lack documentation regarding experimental parameters or don’t include well-defined and structured metadata regarding downstream data processing.
Another example would be in instances where researchers use Electronic Medical Records (EMR). Here, too, data lineage helps them understand how migrating from one EMR software to another impacts the extracted data, bringing to light any potential inconsistencies or biases introduced during data handling.
Highlighting The Differences Between Data Provenance And Data Lineage
So, what’s the core difference between data lineage and provenance?
While both concepts are concerned with the history of data, data provenance underscores the 'where and who' of data origination, and data lineage emphasizes the 'how and where to' of data movement and transformation across diverse systems.
Data Provenance: Emphasizing Data Origins & Creation History
Data provenance addresses questions such as: where the data originated, who created it, when it was collected, and why.
It provides a variety of detail on:
- Data Origin: Extended information on the initial source of the data, including: instruments, experiments, patient encounters, or systems that generated the raw data.
- Data Creation: Detailed records about the data creators, collection methods, and initial context. This gives a deeper understanding of potential biases or limitations inherent in the data.
- Metadata Association: Provenance data itself is a type of metadata with information on the creation and use of data sources.
Data Lineage: Tracking Data Flow And Transformations
Data lineage, in contrast to data provenance, traces the end-to-end journey of data from its upstream sources, moving through systems, processes, and transformations to its downstream consumption points.
Key aspects of data lineage include:
- Flow Visualization: Provides a visual representation of data movement across different systems and stages, highlighting the interconnectedness of data assets.
- Transformation Tracking: Details data transformations and aggregations and identifies the various databases, applications, and tools involved in its lifecycle.
- Impact Analysis: Offers insight on how changes to upstream data sources might affect downstream reports, analyses, and decisions.
Data Lineage Vs Data Provenance - Differences Summarized
Here’s a quick reference table summarizing the main differences between data provenance and lineage.
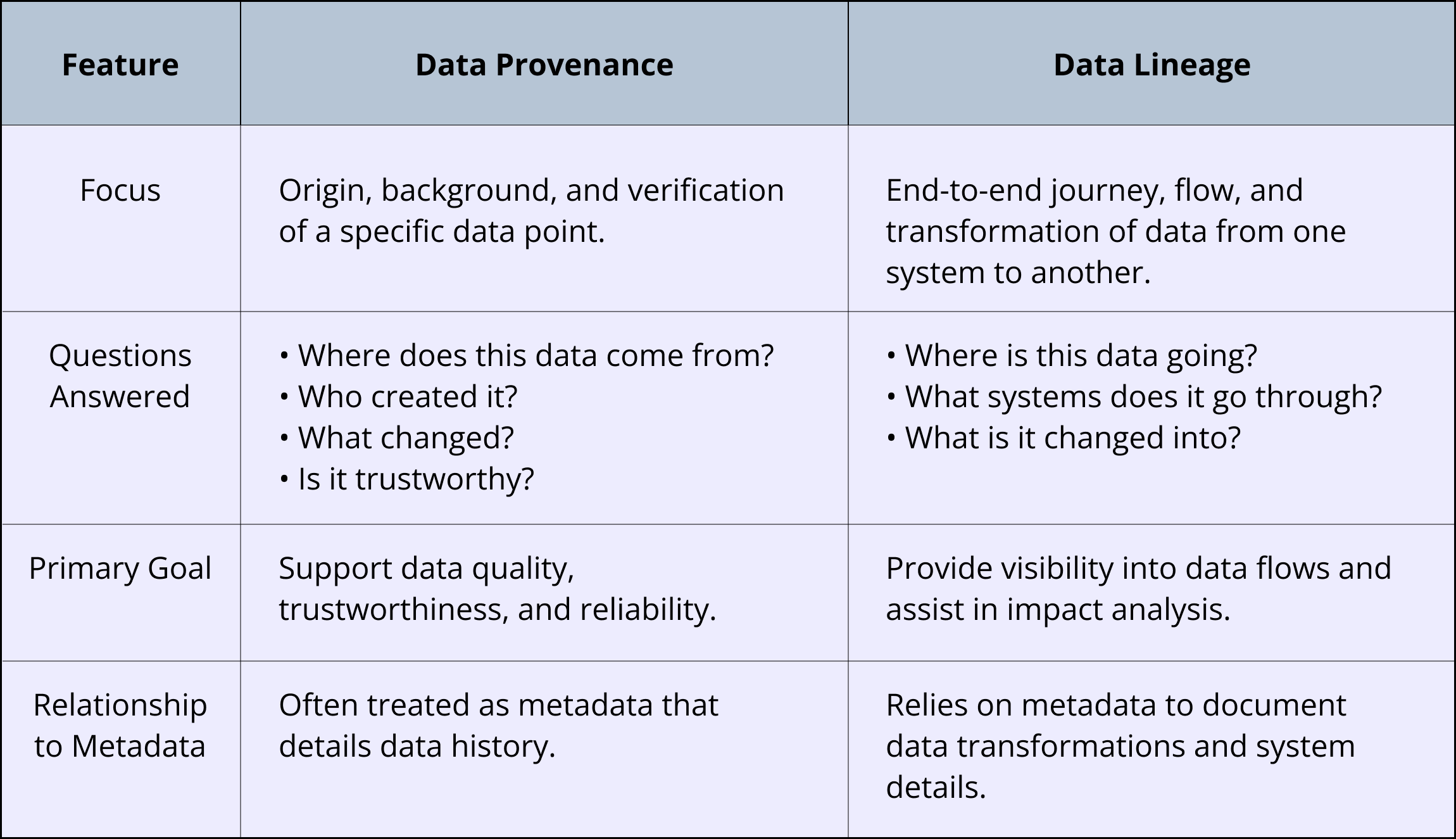
Oftentimes, when scientists talk about data provenance, they also refer to its lineage or vice versa. No matter what, both empower labs to get trusted data, enhance quality and reproducibility, and ultimately contribute to more reliable outcomes for patients and scientific advancement.
How Labbit LIMS Supports Data Provenance & Data Lineage
Designed on FAIR data principles, Labbit stores detailed records of all laboratory workflows in its knowledge graph database, capturing complex, end-to-end relationships between data points.
Labbit helps your lab excel in various ways:
- Captures all sample data and metadata in immutable audit trails for a comprehensive and unalterable record of the data's history.
- Ensures traceability so that information can be tracked through all stages of research.
- Thanks to its knowledge graph technology, Labbit supports interconnected and evolving data models, preserving relationships between data and processes for advanced analysis and a deeper understanding of data lineage.
- Offers rich contextual metadata so that you can better see the context of data and trace its provenance.
- Integrates seamlessly with instruments, external databases, and informatics tools for smooth data flow across systems and connected data records.
So, whether you’re managing samples, orders, or experiments, Labbit ensures your data is organized, accessible, and ready for analysis.



