
Beyond Relational: How Graph Databases Transform FDA-Regulated Recordkeeping

For years, regulated labs have relied on relational databases to store critical data. These systems are built around a collection of database tables and assemble audit trails by piecing together data from these tables. Through this technique these systems provide structures designed for storing records relevant to the laboratory work, from order management to quality control.
However, as data complexity grows and regulatory requirements evolve, relational databases are not necessarily the best choice for modern labs. In fact, as FDA guidance transitions from computer system validation (CSV) to computer software assurance (CSA) and a risk-based framework, regulated laboratories are discovering a core truth: relational databases can store compliant records, but they don’t make it easy. Graph databases, meanwhile, do.
Why Relational Record-Keeping Makes Life Harder Than It Should Be For Labs
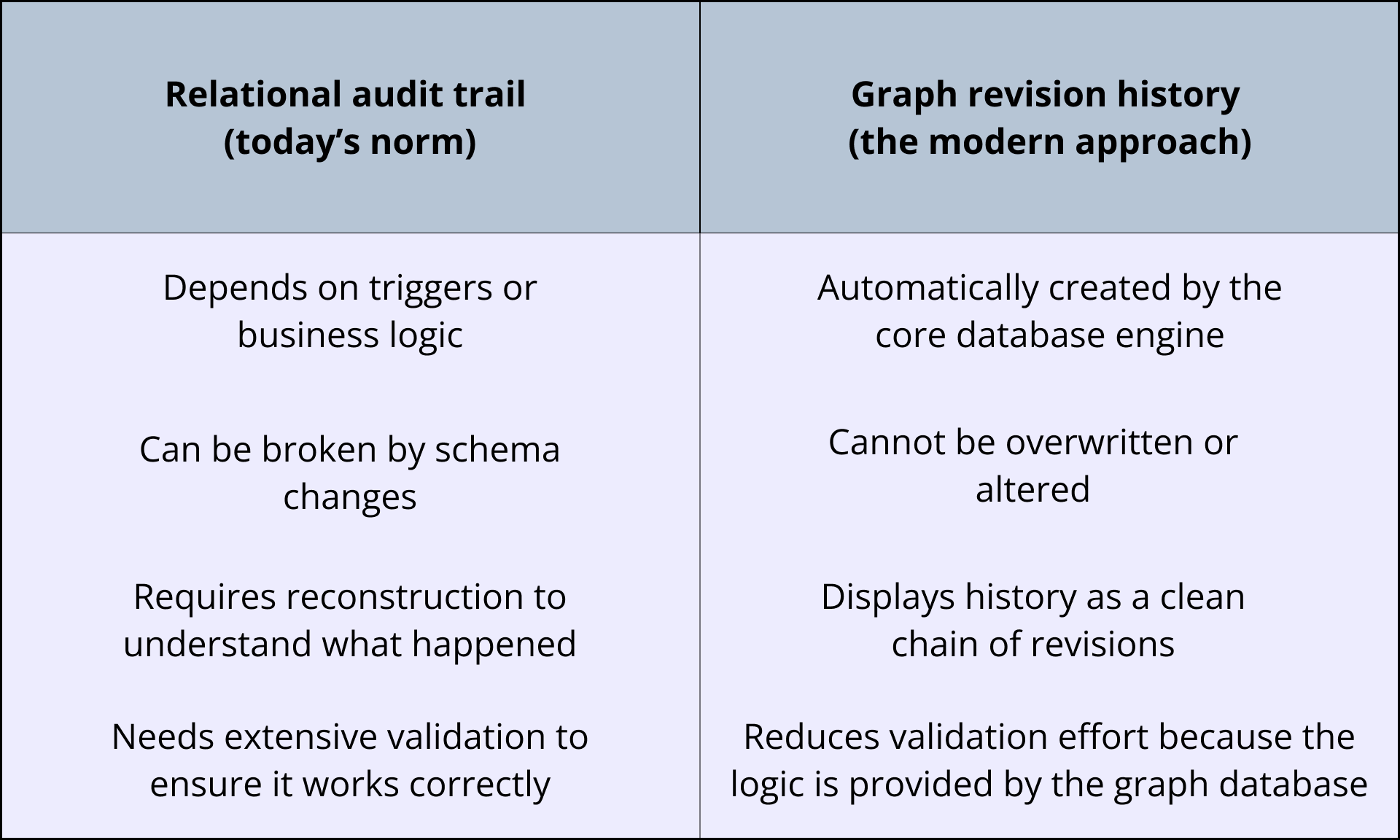
In most traditional laboratory information management systems (LIMS) and solutions built on relational databases, the history of entities is created using a patchwork of techniques. These include audit-trail tables, triggers that copy old rows into shadow tables, version tables with “ValidFrom/ValidTo” date fields, and custom business logic to prevent overwrites.

Although these methods work, they add complexity and risk. History must be reconstructed by joining multiple tables. Hidden failure modes can be introduced if triggers are misconfigured, fields are missing, or incorrect audit logic is applied. More custom code means more test cases and revalidation, and schema changes often break the audit trail.
For labs, the result can be slower investigations, unnecessary corrective actions, heavy validation burden, and additional maintenance overhead.
Immutable Node Revisions Provide Record Integrity Without Workarounds
Graph databases that support immutable node revisions behave differently. Every time a record changes, the database automatically creates a new revision, meaning there is a complete, locked, unchangeable snapshot of the record at that moment in time.

With no row overwrites, no triggers, no risk of missing audit data, and no custom logic to validate, labs can be assured that:
- Every state of every record is preserved permanently.
- Time-stamped, user-stamped history is generated automatically.
- Nothing can be quietly edited or “fixed” retroactively.
- The lineage of a record is stored natively in the system, not reconstructed later.
This directly supports the ALCOA principles (Attributable, Legible, Contemporaneous, Original, and Accurate) for data integrity and eliminates entire categories of test scripts and change controls.
Graph Databases Provide Labs With Several Advantages
Graph databases benefit labs by enabling faster investigations and reducing the amount of time teams spend chasing down discrepancies. Further, they deliver cleaner audit responses, improve regulatory compliance, and ease the burden of validation or assurance tasks.
Streamline Audit Trails
Labs relying on relational databases must continuously engineer and protect a true record history and audit trail. On the other hand, labs using a graph database can be confident that the integrity of their audit trails are inherently guaranteed.
Easily Comply With Regulatory Requirements
Beyond better audit support, graph databases help labs meet regulatory compliance, such as FDA electronic record requirements. FDA 21 CFR Part 11 defines an electronic record as the combination of the data, metadata, and context, as well as a secure, computer-generated audit trail, and protection against alteration.
Graph node revisions inherently include all of this:
- The data values at the time of edit
- Timestamp & user attribution
- State or workflow information
- Relationships to other records
- A tamper-evident, immutable history chain
What this means is that a graph node revision isn’t just storing a version of then electronic record, it is the electronic record that Part 11 describes. This aligns cleanly with the FDA’s data integrity intent as well as EU and other global regulatory requirements, and reduces the lab’s burden when demonstrating compliance.
Simplify CSV And CSA
Systems built on relational databases require validation of the custom audit-trail implementation. That means verifying triggers fire correctly, confirming version tables capture every field, and testing joins and reconstruction logic. Further, you’ll need to retest when schemas change and manage permissions to prevent overwritten history.
Graph-native systems eliminate most of that work. History isn’t customized; it’s a core part of the engine. Because the risky components don’t exist — audit-trail tables, triggers, version tables, and custom business logic — the validation effort drops.
Under the FDA’s new CSA risk-based approach, this is a major advantage. There are fewer scripts to write, less regression testing, smaller validation packages, clearer evidence for auditors, and reduced long-term maintenance cost. At the same time, lab teams and their consultants can develop more efficient implementations and generate cleaner documentation.
Labbit’s “History View” Lets The System Tell The Story
Labbit is a real-world example of a modern informatics solution built on a graph database. With all the inherent benefits of this foundation, Labbit takes the native revision chain and turns it into something intuitive and usable: the History View.
Instead of clicking through audit-trail reports or comparing database snapshots, users see a chronological, narrative-style timeline for an entity. Details include:
- What changed
- Who changed it
- When it changed
- Why it changed
- How it related to other records at that moment
.png)
This mirrors how investigators, auditors, and quality reviewers naturally think. Rather than decoding the audit trail, users simply read it. For labs, this reduces time spent piecing together workflows during OOS (Out of Specification), OOT (Out of Trend), and CAPA (Corrective and Preventive Actions) investigations. It also means less effort in developing custom reports to uncover this information and more time to focus on process improvement or other innovations.
Graph Databases Offer A Better Mechanism For Storing And Accessing Lab Data
Graph-native recordkeeping is not a gimmick, a luxury, or a theoretical complication. It directly improves how your lab operates by supporting:
- Faster and clearer investigations based on a clear, trustworthy history that is readable and complete.
- Easier audit responses because lineage is visible and tamper-evident.
- Reduced validation burden because audit integrity is built in, not engineered.
- Less data integrity risk because overwrites and silent failures become impossible.
- Simpler change management because core recordkeeping logic doesn’t break when the system evolves.
- Immutable revisions that align naturally with FDA and other regulatory body expectations.
These are practical, day-to-day operational wins, not abstract technology improvements. Modern informatics platforms like Labbit, which is built on a graph database, make these benefits accessible without requiring your lab team to become database experts.
It’s time to move beyond the constraints of relational databases and fragile audit-trail workarounds toward a recordkeeping model designed from the ground up for integrity, clarity, and compliance.


